Can You Move These Over There? An LLM-based VR Mover for Supporting Object Manipulation
Xiangzhi Eric Wang, Zackary P. T. Sin, Ye Jia, Daniel Archer, Wynonna H. Y. Fong, Qing Li, Chen Li
Proceedings of the 38th Annual ACM Symposium on User Interface Software and Technology (2025)
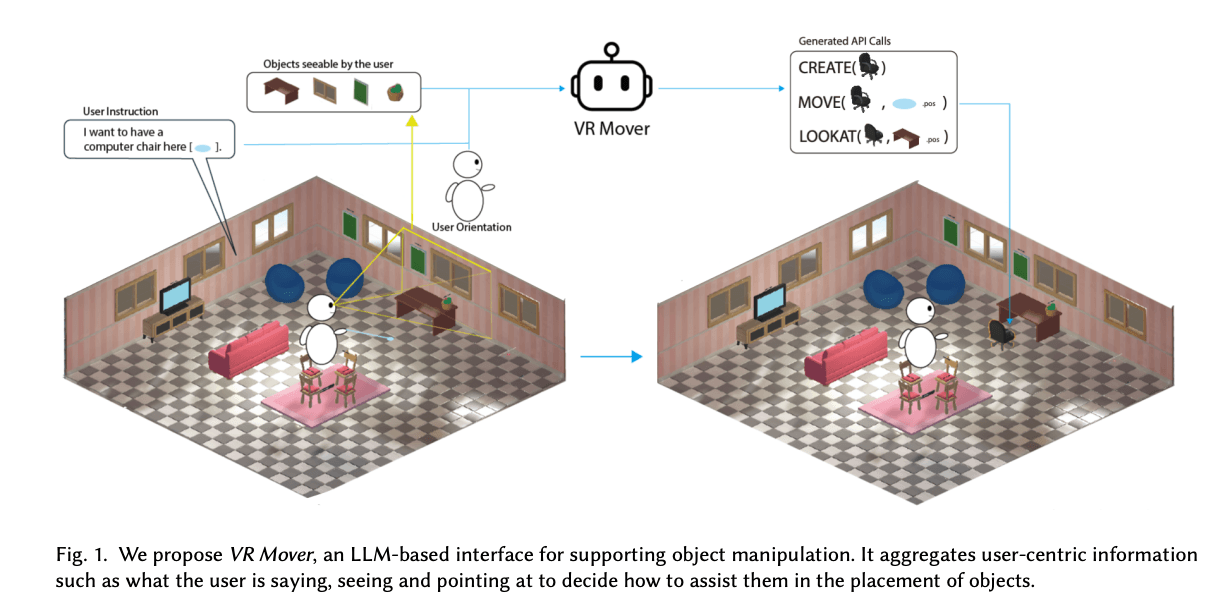
We propose VR Mover, an LLM-based interface for supporting object manipulation. It aggregates user-centric information such as what the user is saying, seeing and pointing at to decide how to assist them in the placement of objects.
Abstract
In our daily lives, we can naturally convey instructions for the spatial manipulation of objects using words and gestures. Transposing this form of interaction into virtual reality (VR) object manipulation can be beneficial. We propose VR Mover, an LLM-empowered solution that can understand and interpret the user's vocal instruction to support object manipulation. By simply pointing and speaking, the LLM can manipulate objects without structured input. Our user study demonstrates that VR Mover enhances user usability, overall experience and performance on multi-object manipulation, while also reducing workload and arm fatigue. Users prefer the proposed natural interface for broad movements and may complementarily switch to gizmos or virtual hands for finer adjustments. These findings are believed to contribute to design implications for future LLM-based object manipulation interfaces, highlighting the potential for more intuitive and efficient user interactions in VR environments.
The Object Manipulation Gap in VR
VR object manipulation has converged on two paradigms: gizmos (3D widgets with handles for translation, rotation, and scale) and virtual hands (direct grabbing and placing, mimicking real-world manipulation). Both work, but both have weaknesses that intensify as the number of objects grows. Gizmos are precise but tedious — selecting each object individually, switching between translation and rotation modes, aligning handles with target positions. Virtual hands are intuitive but fatiguing — reaching across a large virtual space to place objects strains the arms, and precision suffers at distance. Neither paradigm exploits the most natural human strategy for delegating spatial tasks: telling someone else to do it.
VR Mover explores a third paradigm: delegated manipulation through natural language and pointing. Instead of manipulating objects directly, the user points at what they mean and says what they want — "put these chairs around that table," "move this closer to the window," "line these up against the wall." An LLM interprets the instruction, identifies the relevant objects from the user's gaze and pointing direction, and executes the spatial transformation.
How Delegated Manipulation Works
The system integrates three input streams: speech (the user's verbal instruction, transcribed via ASR), pointing/gaze (what the user is looking at or pointing toward, captured via controller raycast or eye tracking), and scene context (the spatial layout of objects in the current VR environment). These streams are combined into a prompt that describes: the user's words, the objects in the scene with their positions and types, and which objects are in the user's focus. The LLM resolves the referential ambiguity — "these" = the three chairs the user is pointing at, "over there" = the empty corner of the room, "around" = arranged in a semicircle facing inward — and generates the sequence of spatial transformations.
This is a meaningfully different use of LLMs than the dominant paradigm of chatbot-style interaction. The LLM is not generating text for the user to read; it's generating spatial operations that the system executes. Its role is intent resolution — mapping imprecise natural language onto precise geometric transformations. This is closer to how programming language compilers work (source code → machine operations) than to how chatbots work (prompt → response text).
The User Study
The study compared VR Mover against gizmos and virtual hands in multi-object manipulation tasks — scenarios where users needed to arrange, group, and reposition multiple objects in a virtual environment. The tasks were designed to be ecologically representative: setting up a virtual meeting room, organizing a gallery space, arranging furniture in a room layout.
Results showed that VR Mover improved usability, overall experience, and task performance for multi-object manipulation, while reducing workload and arm fatigue. The workload reduction is straightforward: instead of physically reaching for and manipulating each object, users delegate the physical work to the system. The arm fatigue reduction is similarly intuitive: pointing and speaking is less physically demanding than grabbing and placing, especially for repeated operations across a large workspace.
The most interesting finding is the complementarity pattern: users did not abandon gizmos and virtual hands entirely. They used VR Mover for broad, coarse movements ("put all the chairs around the table") and then switched to gizmos or virtual hands for fine adjustments ("this chair needs to be rotated 15 degrees left"). This suggests that delegated manipulation is not a replacement for direct manipulation but an additional layer in a manipulation stack — coarse delegation for spatial planning, fine direct manipulation for precision placement. The optimal VR interface may be one where users fluidly switch between these layers depending on the granularity of the current operation.
Design Implications
The complementarity finding has a specific design implication: VR Mover-like systems should not attempt to handle every manipulation. The LLM should be optimized for the types of spatial reasoning that are tedious for humans (multi-object arrangement, relative positioning, spatial pattern application) and should gracefully hand off to direct manipulation for tasks that require the user's fine motor control and spatial judgment. A system that tries to do everything via natural language will fail on precision; a system that only does direct manipulation will exhaust users on scale. The sweet spot is an interface that knows when to delegate and when to get out of the way.
A second implication concerns error recovery. When an LLM misinterprets "move these over there" — placing chairs in the wrong corner, arranging them in a line instead of a circle — the cost of correction must be low. The current system supports undo, but the paper does not deeply explore correction strategies. A production system would need to support incremental refinement through follow-up speech ("no, closer together," "rotate them to face the window") without requiring the user to revert to full direct manipulation.
Boundaries
VR Mover requires precise scene understanding — the system must know what objects exist, where they are, and what they're called. In the study, this was provided through predefined object metadata. In an arbitrary VR environment where objects lack semantic labels, the system would need scene understanding (computer vision or manual annotation) that the current implementation doesn't address.
The LLM's spatial reasoning is only as good as the scene description in the prompt. Complex spatial relationships ("arrange these in a Fibonacci spiral pattern") or ambiguous references ("that thing next to the other thing") will produce errors that the user must catch and correct. The study doesn't characterize the failure modes systematically — we know VR Mover helps on average, but we don't know which types of spatial instructions it reliably handles and which it systematically fails on. This failure-mode taxonomy is necessary before VR Mover can be deployed in applications where spatial accuracy is critical (architecture, engineering, surgical planning).
The study also doesn't address multi-user scenarios where multiple people are pointing and speaking simultaneously, or where one user's instruction conflicts with another's. In collaborative VR environments, resolving who "these" and "over there" belong to becomes a social coordination problem on top of a technical one.
Related News & Timeline
- Published Online
Paper Published Online
The final version is now available online. https://doi.org/10.1145/3746059.37476